Chris is.
and 2 others
boosted

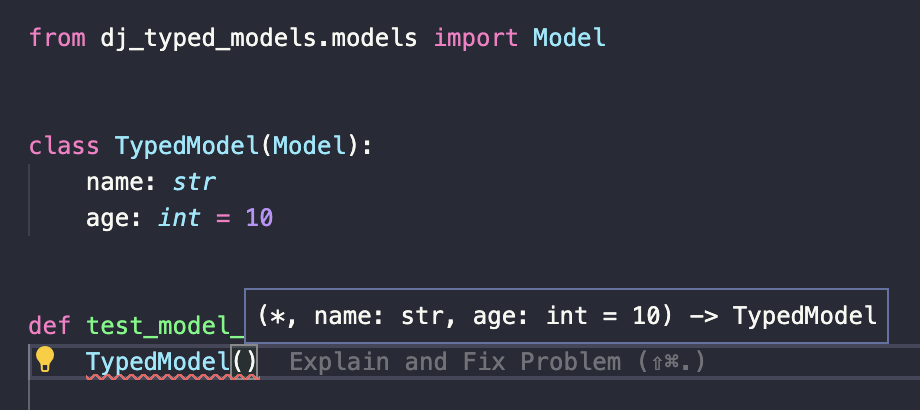
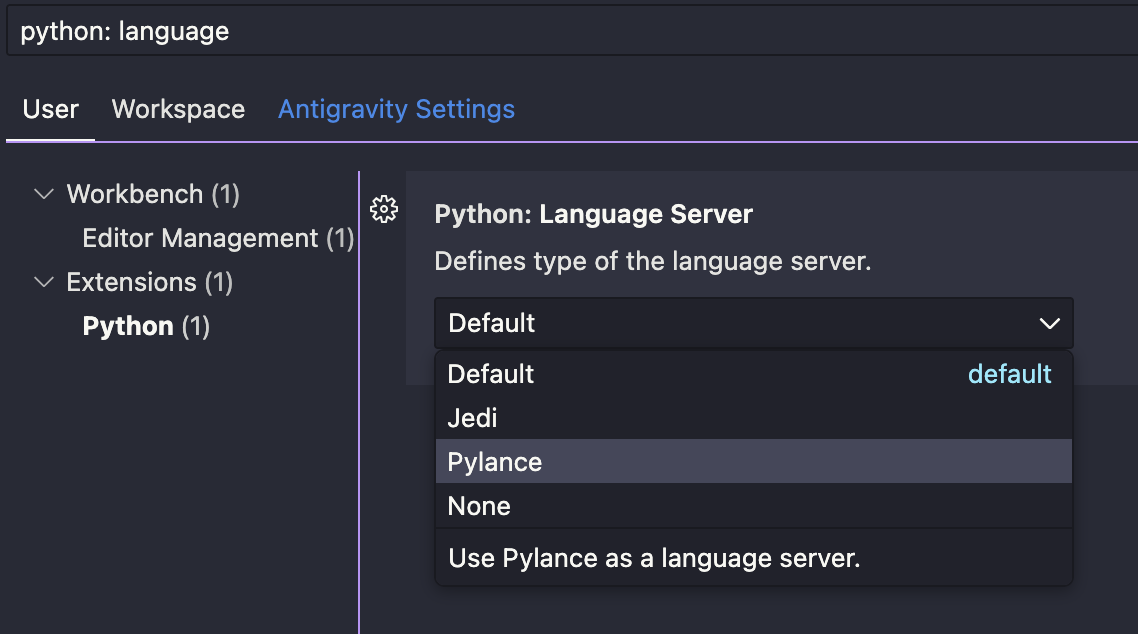
As promised:
I'm a staff-ish level software engineer, fairly deeply involved in the Python community (see @NorthBayPython which I organise, and @ThePSF where I'm a board Director). Things I like: understanding/taking apart/reassembling systems; open source; technology in service of humans. Otherwise not terribly picky :)
Things I'm good at: programming in #Python (other languages acceptable, of course), communicating complicated stuff in conference talks, probably a few things related to that. Ask?